Intro to Statistics: Part 7: Common Distribution Patterns
Let's go over a few of the most common distribution patterns you'll come across, along with their corresponding probability density functions.
The Normal distribution
The mother of all distributions is the normal distribution. The normal distribution is commonly found in nature. The probability density function for the normal distribution is given by the following formula:

Aside: you'll probably never need to know this formula. If you're only interested in learning how to understand and apply statistical concepts, then some of the mathematical details aren't so important.
The shape of the probability density function for a normal distribution is governed by two parameters: the mean and standard deviation. The figure below charts four different probability density functions for four different normal distributions, each with different values for mean and standard deviation.

http://en.wikipedia.org/wiki/Normal_distribution
The mean (expected value) of the distribution determines the peak of the curve -- i.e. the outcome value with the highest probability density. The standard deviation of the distribution determines how wide the curve is. Larger standard deviation gives you a wider curve, smaller standard deviation gives you a narrower curve (and a taller peak).
Remember that standard deviation is the square root of variance, and variance tells us how "spread out" the data are. So it makes sense that larger variance results in a wider curve. Larger variance means the probability densities are spread out across a wider range of outcome values, whereas smaller variance means the the densities are tightly clustered within a more narrow range of outcomes.
Let's quickly remind ourselves what the normal distribution curve is telling us. It's centered around the mean of the distribution, where the mean outcome has the peak probability density, and the probability density for all other outcomes tails off in both directions, symmetrically. In other words, you're most likely to observe an outcome near the mean. The further away from the mean, the less likely you'll observe that outcome. The distribution of heights that we looked at in previous articles follows this pattern.
R functions for the normal distribution
- dnorm: (d = density): Takes an outcome value as input and returns its density
- pnorm: (p = probability): Takes an outcome value as input and returns the probability of observing an outcome less than or equal to the given outcome (i.e. the range from -infinity up to the given outcome)
- qnorm: (q = quantile): Takes a probability value (a "quantile") and returns the corresponding outcome such that the probability of observing an outcome less than or equal to the returned outcome is equal to the given probability
- rnorm: (r = random): Generates random values that follow a normal distribution pattern
The Bernoulli Distribution
The Bernoulli distribution is a distribution pattern for discrete random variables with binary outcomes. Binary means the set of outcomes contains only two possible values.
We haven't talked about the distinction between discrete and continuous random variables. The distinction is probably intuitive, but just to spell it out:
- A discrete random variable is one in which the set of outcomes takes on discrete values.
- A continuous random variable is one in which the set of outcomes can take on any real number within the range of possible outcomes.
The die roll is an example of a discrete random variable: the set of outcomes contains the discrete integers, 1 - 6. The heights of people is an example of a continuous random variable: the set of outcomes includes any real number that could represent a height.
A Bernoulli distribution applies specifically to discrete random variables that generates binary outcomes -- i.e. the set of outcomes contains only two values. The coin flip is an example of a binary outcome: the outcome can either be heads or tails. Typically binary outcomes are converted to the values 0 and 1, for number-crunching purposes.
The probability mass function for a bernoulli random variable is given by:

...where:
- k is the outcome value (either 0 or 1)
- p is the probability of observing a 1
The probability mass function is the discrete version of the probability density function. Probability density functions apply to continuous random variables; probability mass functions apply to discrete random variables. They basically serve the same purpose, but there are a few notable differences. For one, a probability density function is a continuous function, whereas a probability mass function is a discrete function. Secondly, and more importantly, a probability density function returns the probability density for a given outcome, whereas a probability mass function returns the actual probability for a given outcome.
So let's think about what the probability mass function for a bernoulli random variable tells us. It takes an outcome value, k, which can be either 0 or 1, and a probability, p, which is the probability of observing a 1. If we plug both possible outcomes into the equation, we get:
![\begin{align*}f(k=0,p) & = p^0 \cdot (1-p)^{1-0}\\[8pt] & = 1 \cdot (1-p)^1\\[8pt] &= (1-p)\end{align*}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430509208019-MN9KFW4P9WYCWCQVJ7CG/image-asset.png)
![\begin{align*}f(k=1,p) & = p^1 \cdot (1-p)^{1-1}\\[8pt] & = p \cdot (1-p)^0\\[8pt] &= p\end{align*}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430509272797-FA8R5O915XXIK6ECOFYH/image-asset.png)
So the probability of observing a "0" is (1 - p), and the probability of observing a "1" is p. This makes sense. If you only have two possible outcomes, and the probability of one of them is p, then the probability of the other must be (1 - p), because the sum of probabilities for all outcomes must equal 1.
For the coin flip example, we can assign the values 0 and 1 however we want. Let's say heads is 0 and tails is 1. Assuming the coin is fair, the probability of observing a 1 (tails), is p = 0.5. That means the probability of observing a 0 (heads), is (1 - p) = 0.5. If the coin were biased, such that tails turned up about 70% of the time, then the probability of observing a 1 (tails) is p = 0.7, and the probability of getting a 0 (heads) is (1 - p) = 0.3.
Expected value and variance of the Bernoulli distribution
We can compute the expected value and variance for a Bernoulli distribution by simply applying the formulas
![\begin{align*} \operatorname{E}[X] & = \sum_{i=1}^{k}x_i\cdot p_i\\[8pt] & = 0 \cdot (1-p) + 1 \cdot p\\[8pt] & = p\end{align*}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430503260718-SIFLV3EHY7KHV07B48VY/image-asset.png)
![\begin{align*}\operatorname{Var}(X) & = \sum_{i=1}^k p_i\cdot(x_i - \mu)^2 \\[8pt] & = (1-p)\cdot (0 - \operatorname{E}[X])^2 + p\cdot (1 - \operatorname{E}[X])^2\\[8pt] & = (1-p)\cdot (0 - p)^2 + p\cdot (1 - p…](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430503934632-RRZ7OB26HA928ZTE7X2G/image-asset.png)
The binomial distribution
The binomial distribution is another example of a discrete probability distribution. The binomial distribution describes the distribution of a binomial random variable. A binomial random variable represents the outcomes generated by a series of Bernoulli trials. A Bernoulli trial is the process of conducting an experiment on a Bernoulli random variable and observing the outcome. A Bernoulli random variable, as discussed above, has only two possible outcomes, 0 and 1. The outcome for a binomial random variable is the number of 1's (a.k.a "successes") observed in the series of Bernoulli trials.
The probability mass function for the binomial distribution gives the probability of observing a given number of successes (1's), out of a given number of bernoulli trials. It's formula is given by:
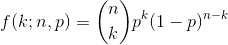
where...
- p is the probability of observing a 1 (the p of the underlying Bernoulli random variable)
- n is the number of bernoulli trials
- k is the number of successes (1's) observed in the n trials
The function takes as input the number of trials, n, and a given number of successes, k, and returns the probability of observing the given number of successes in the given number of trials.
The chart below depicts the probability mass functions for three different binomial distributions, each with differing values for p and n. The k values -- the number of successes -- are the outcome values of the distribution, given along the x axis. The y axis indicates the probability of observing those outcomes.

http://en.wikipedia.org/wiki/Binomial_distribution
Let's focus on the red curve, with p = 0.5 and n = 40. What's the curve telling us? Well, the highest probability is associated with the outcome k = 20. This means that, given the probability of a "successful" Bernoulli trial being p = 0.5, then out of n = 40 trials you're most likely to observe k = 20 successes.
For example, if the underlying bernoulli variable represented a coin flip, with "tails" meaning "success", then the binomial distribution tells you that, if you flipped the coin n = 40 times, you're most likely to observe k = 20 heads. The probability decreases as you move further away from k = 20. By the time you get to the extremes, k = 0 and k = 40, the probability has dropped to nearly 0. This makes sense: if you flipped a coin 40 times, the chance of them all being tails or all being heads is quite unlikely.
Expected value and variance of the binomial distribution
The expected value of a binomial distribution is simply the number of trials multiplied by the probability of success. Note that the probability of success is the same as the expected value of the underlying Bernoulli random variable that the binomial series is generated from. So the expected value of a binomial distribution is equal to the expected value of the underlying Bernoulli random variable multiplied by the number of trials. Similarly the variance of a binomial distribution is equal to the variance of the underlying Bernoulli random variable multiplied by the the number of trials.


R functions that deal with the binomial distribution
- dbinom: (d = density): takes an outcome value k, along with the number of trials n and the probability of success p, and returns the probability of observing k successes.
- pbinom: (p = probability): takes an outcome value k, along with the number of trials n and the probability of success p, and returns the probability of observing less than or equal to k successes (i.e the range of -infinity to k).
- qbinom: (q = quantile): takes a probability, along with the number of trials n and the probability of success p, and returns the number of successes at which the probability of observing that number of successes or fewer is equal to the given probability.
- rbinom: (r = random): generates a series of random values that behave according to the binomial distribution.
The uniform distribution
The uniform distribution applies to random variables whose outcomes all have equal probability of occurring. There are two forms, one for discrete random variables and one for continuous random variables. The two forms are very similar although there are some slight differences. The probability density function of the continuous uniform distribution (first formula) and the probability mass function of the discrete uniform distribution (second formula) are shown below:
![f(x)=\begin{cases}\frac{1}{b - a} & \mathrm{for}\ a \le x \le b, \\[8]0 & \mathrm{for}\ x<a\ \mathrm{or}\ x>b\end{cases}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430504832482-906K29S9IC20F4DQO3FG/image-asset.png)
![f(x)=\begin{cases}\frac{1}{b - a + 1} & \mathrm{for}\ a \le x \le b, \\[8]0 & \mathrm{for}\ x<a\ \mathrm{or}\ x>b\end{cases}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430504861196-T6YJUPBGZRFXCX9T04JA/image-asset.png)
Note the only difference between the two is the denominator term: (b - a) for continuous and (b - a + 1) for discrete. The +1 is just a side effect when dealing with discrete values. (b - a + 1) is the total number of discrete outcomes between a and b, including a and b. (b - a) is the size of the range between a and b. For example if you have a 6-sided die, then a = 1, b = 6, and the number of outcomes is 6 - 1 + 1 = 6. However if you have some continuous random variable whose outcomes fall somewhere between 1 and 6, then the size of the range is 6 - 1 = 5 (not 6, which would be the range between 0 and 6, not 1 and 6).
All outcomes in a uniform distribution have equal probability. Remember that the probability density function returns the probability density of a given outcome, whereas the probability mass function returns the actual probability of a given outcome. The probability density returned by the density function can be multiplied by a given range of interest to compute the probability of observing an outcome in that range. Since the probability density for the uniform distribution is constant for all possible outcomes, computing the probability is easy: it's just the area of the rectangle, with height = 1 / (b - a) and width = {range of interest}.
The die roll is an example of a discrete random variable with a uniform distribution. We can plug any possible outcome value into the probability mass function to get the probability of observing that outcome. Note that the same probability is returned for every outcome, since the probability mass function does not depend on the outcome value itself.
probability(die=1) = 1 / (b - a + 1) = 1/6
probability(die=2) = 1 / (b - a + 1) = 1/6
...
Similarly, imagine a continuous random variable that can take on any real number between 0 and 10. The probability density is the same for every possible outcome value: 1 / (b-a) = 1 / 10. We can multiply the density by the width of the range to determine the probability of an outcome falling in that range. For example, the probability of an outcome falling in the range between 0 and 1 would be 1 / 10 * 1 = 0.1. The probability of an outcome falling in the range between 4 and 7 is 1 / 10 * (7 - 4) = 0.3.
The following charts graph the probability density function of the continuous uniform distribution (first chart) and the probability mass function of the discrete uniform distribution (second chart - note that n = b - a + 1).


Expected value and variance of a uniform distribution
The expected value of both the continuous and discrete forms of the uniform distribution is:
![\operatorname{E}[X] = \frac{(b + a)}{2}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430510323377-NF2T1IJG7J4N35RGSLFE/image-asset.png)
The variance of the uniform distribution is:

where n is the number of possible outcomes.
R functions that deal with the uniform distribution
- dunif: (d = density): Takes the min and max of the distribution and a given outcome value and returns the probability density of the given outcome
- punif: (p = probability): Takes the min and max of the distribution and a given outcome value and returns the probability of observing an outcome less than or equal to the given outcome (i.e. the range from min to the given outcome)
- qunif: (q = quantile): Takes the min and max of the distribution and a probability and returns the outcome value such that the probability of observing an outcome less than or equal to the returned outcome is equal to the given probability
- runif: (r = random): Generates random values that follow a uniform distribution
The Poisson distribution
The Poisson distribution is another example of a discrete probability distribution. It's useful for modeling counts of things, for example the number of times some event occurs in a given interval of time. The shape of the distribution curve is governed by the rate parameter, denoted as λ, which gives the average frequency at which the events are known to occur.

http://en.wikipedia.org/wiki/Poisson_distribution
What does the Poisson distribution tell us? Well it can answer questions like, "what's the probability of observing k events in an interval of time t if those events are known to occur with an average rate of λ. The rate parameter, λ, is usually expressed in units of n / t, where n is the average number of events per unit of time. In order to plot the distribution for a certain interval of time, you'd multiply the λ value by the time interval t to give you the λ value to use when plotting the distribution curve for that particular interval.
So, for example, imagine we wanted to know the probability of observing k = 5 events in a time interval of, say, 4 hours, where the average rate of the event occuring is 1 event / hour. The λ value for our distribution is λ = 1 event / hour * 4 hours = 4. This distribution is shown in the chart above, using purple dots. As you can see the probability of observing precisely 5 events is about 0.16 or so, which is slightly less than observing 4 events, which makes sense given the value of λ.
For another example, imagine instead that the average rate is 2.5 events / hour. Now our λ value is 2.5 events / hour * 4 hours = 10. The distribution for λ = 10 is shown by the blue dots. In this case, the probability of observing precisely k = 5 events is much smaller, just 0.04 or so. This is because our rate has increased, so the likelihood of observing only 5 events in the time interval is quite small. We are more likely to observe 10 events, or thereabouts, as indicated by the distribution curve.
Expected value and variance of the Poisson distribution
The expected value of a poisson distribution is equal to λ. Note in all the curves above, the λ value has the peak probability. The variance of a poisson distribution is also equal to λ.
![\begin{align*}\operatorname{E}[X] = \lambda\\ \\\operatorname{Var}(X) = \lambda\end{align*}](https://images.squarespace-cdn.com/content/v1/5533d6f2e4b03d5a7f760d21/1430507106805-U7HG6SW9BL0NXBIHSJCY/image-asset.png)
R functions that deal with the Poisson distribution
- dpois: (d = density): Takes the λ value and a given number of events and returns the probability of observing the given number of events exactly.
- ppois: (p = probability): Takes the λ value and a given number of events and returns the probability of observing the given number of events or fewer (i.e. the range from 0 to the given number of events).
- qpois: (q = quantile): Takes the λ value and a probability and returns the number of events such that the probability of observing the returned number of events or fewer is equal to the given probability
- rpois: (r = random): Generates random values that follow a Poisson distribution
Recap
- A random variable is described by the characteristics of its distribution
- The expected value, E[X], of a distribution is the weighted average of all outcomes, where each outcome is weighted by its probability
- The variance, Var(X), is the "measure of spread" of a distribution. It's calculated by taking the weighted average of the squared differences between each outcome and the expected value.
- The standard deviation of a distribution is the square root of its variance
- A random variable's distribution is commonly plotted using probability density function for continuous random variables and a probability mass function for discrete random variables
- A probability density function for continuous random variables takes an outcome value as input and returns the probability density for the given outcome
- A probability mass function for discrete random variables takes an outcome value as input and returns the actual probability for the given outcome
- The probability of observing an outcome within a given range can be determined by computing the area under the probability density function curve within the given range.
- A sample is a subset of a population. Statistical methods and principles are applied to the sample's distribution in order to make inferences about the true distribution -- i.e. the distribution across the population as a whole